fVision
fVision
Challenging the lack of diversity in luxury creative direction, this project uses AI to visualise fashion houses through a female perspective.
Concept.
This idea was sparked by the viral news that Sarah Burton had stepped down as creative director of Alexander McQueen, succeeded by Irish designer Seán McGirr. The decision drew criticism, as all of Kering’s major fashion houses—McQueen, Gucci, Bottega Veneta, Saint Laurent, and Balenciaga—are now led by white men.
From a female perspective, I want to respond to this shift by spotlighting emerging women designers whose work I admire. Using AI, I’ll merge the aesthetics of Kering’s current male-led collections with the distinctive styles of these independent female voices, imagining how they might reinterpret the brands’ historical legacies if given the creative reins.
Appearance:

steps
Data Scraping
AutoEncoder VAE
I decided to try the AutoEncoder VAE with a similar dataset- this are the results → not very good either after 100 epochs.
I had to have a change in plans and realise that I need to keep adding images so I can get better quality and then decide with which one I want to proceed.
I decided to combine multiple women fashion designers instead of just one and add them to the database to do a collective aesthetic and hopefully get better results.
I also transitioned from product photos to photos from the runway as its easier to keep the same format.

DCGAN - Deep Convolutional Generative Adversarial Network
I initially opted to utilise this model for training because of its capability to generate novel images based on the dataset of garments. This approach allows the model to learn intricate details and patterns from the existing designs. Moreover, I plan to leverage interpolation techniques, which will enable the model to blend and interpolate between different styles and elements present in both the current designs by male creative directors and those envisioned by the young female designers I admire.

Epoch 40:

Epoch 100:

Because the quality of the images remained absolutely horrible no matter what, I decided to resize them from 64 to 256 pixels. From there, I went through a lot of tweaking to adjust the code, which was originally built for 64-pixel images, to work with 256-pixel images. Despite my efforts, I couldn’t figure out how to make it work, so I asked for help online. Finally, I added enough layers to the generator and discriminator to achieve the desired shape, but this time the content was just noise.
Real images:

SPLICE AI
It is a model that essentially takes two images and combines them. While I would have preferred the AI to learn the styles of two different designers and generate new designs blending both styles, this was my next best option. In hopes of achieving a proper result, I began working on it.
Splice AI draws inspiration from Neural Style Transfer (NST) that represents content and an artistic style in the space of deep features encoded by a pre-trained classification CNN model.
I downloaded one image from the latest Bottega collection and another from DI PETSA, a small independent Greek fashion designer. After tweaking the code to operate independently of Google Collab and use images from my folder, I managed to generate this image:
Appearance:

I chose to adjust the transformers code provided by the original AI. Given that men's fashion is generally simpler and features fewer patterns, I found it necessary to modify the transforms. I altered the crop size, the probabilities for horizontal and colour jitter, the kernel size, and the Gaussian blur.
Structure:

Structure:

Result:


Appearance:

Appearance:
Structure:

Result:
Result:


Structure:

Appearance:

Structure:

Result:

Fake images:

Result:

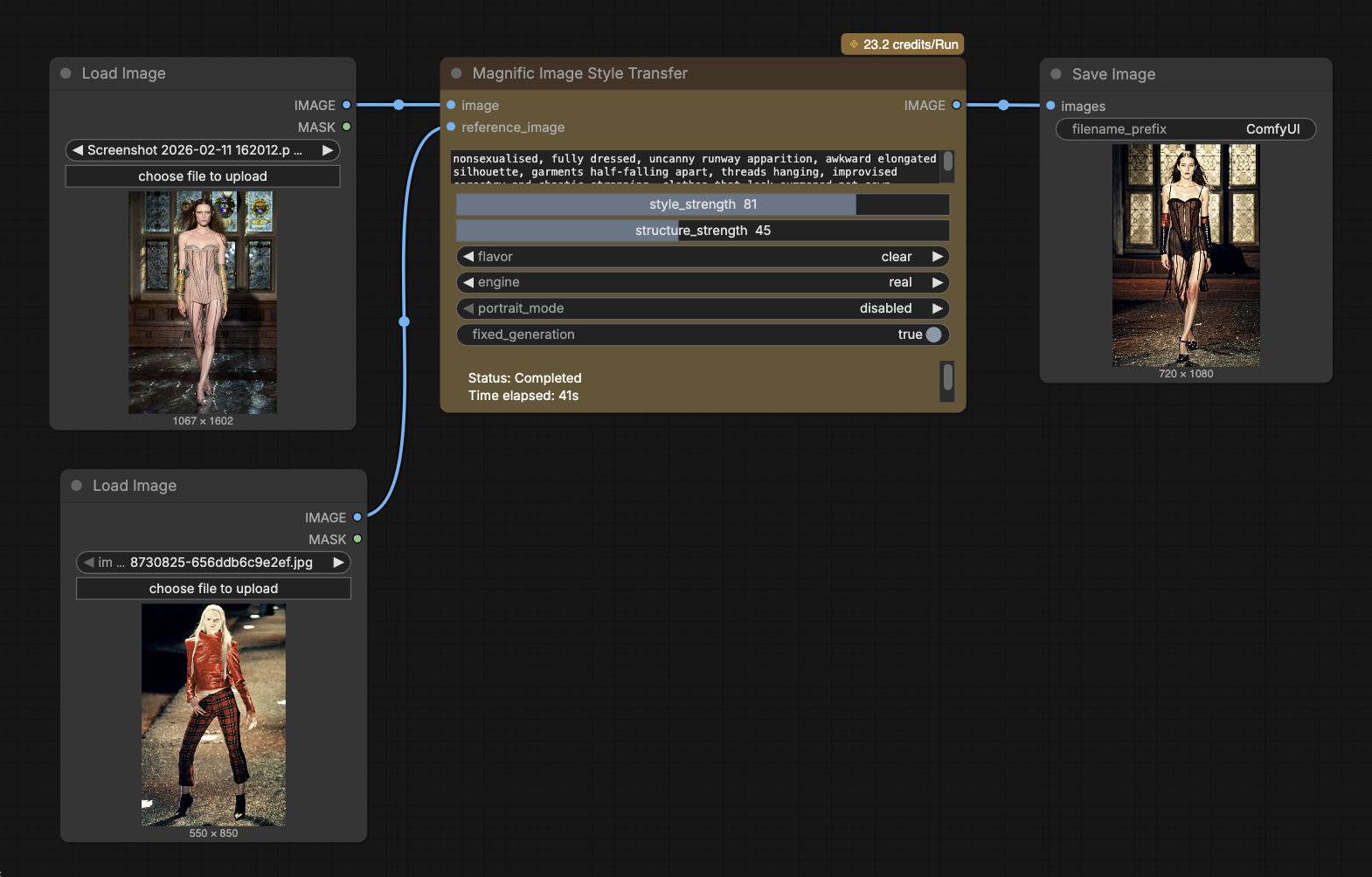
ComfyUI

aggregates up to four reference images into a reusable style configuration object that can be passed downstream to Recraft image generation nodes for consistent stylistic control.
Outputs
Dilara Findikoglu for Alexander McQueen

Recraft Create Style

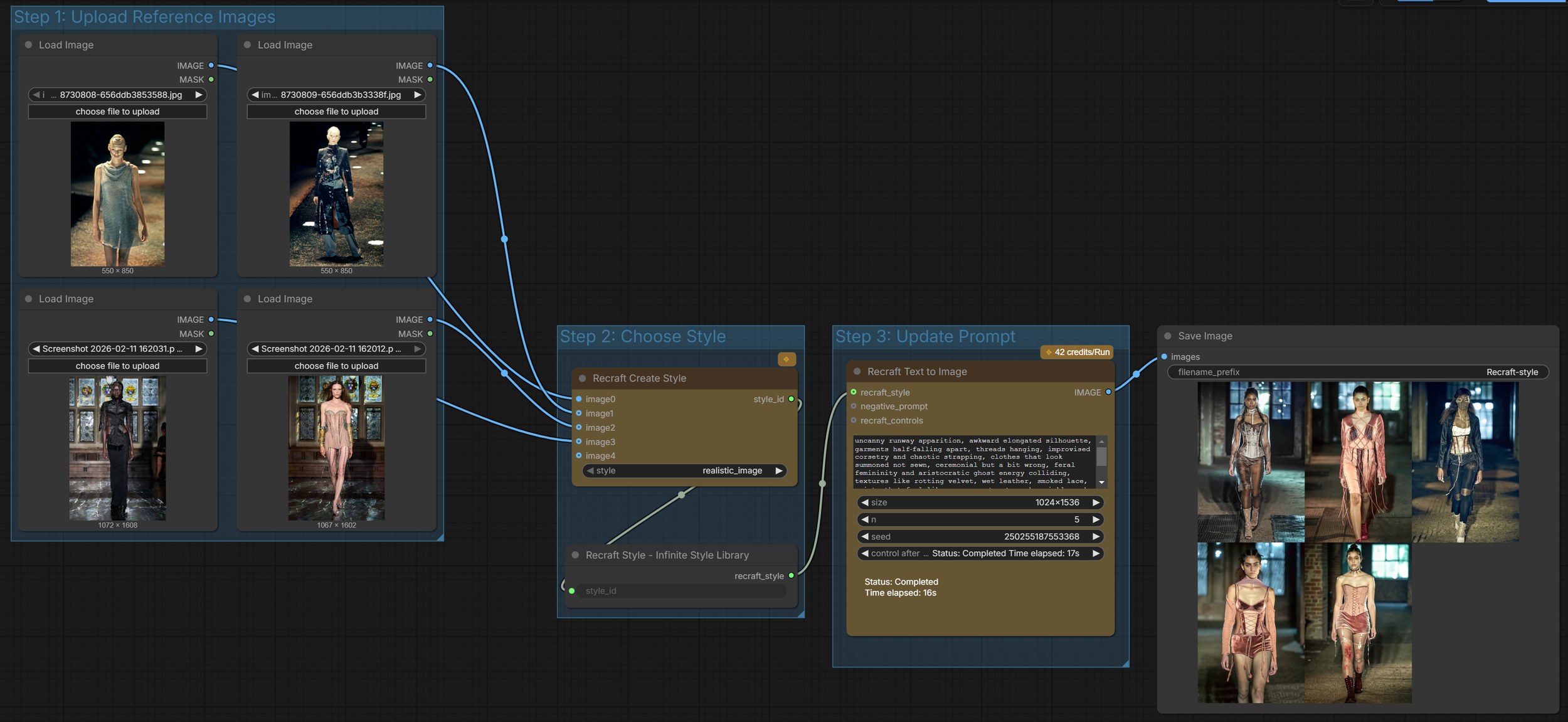





Image Style Transfer
takes two inputs — a style reference image and a structure (content) image — and conditions the diffusion model so that the output preserves the target image’s composition while adopting the reference image’s visual style